Streamlit을 사용한 공공데이터 전처리 & 시각화
Streamlit이란 무엇이고 왜 필요한가?
오늘 글에서는 제가 평소에 많이 활용하고, 상당히 애정하는 Streamlit이라는 파이썬 데이터 웹앱 프레임워크를 소개하려고 합니다.
파이썬 데이터 분석을 처음 배울 때 대부분 주피터 노트북 (Jupyter Notebook)으로 시작하는데, 이는 순수 파이썬 파일(.py)에서 작업하는 것에 비해 데이터의 모양과 형태, 그래프 등을 그때 그때 봐야하는 작업 특성과 주피터 노트북의 셀별 실행 환경이 잘 어울리기 때문이라고 생각합니다.
저도 그렇기에 처음 파이썬을 배웠을 때부터 주피터 노트북과 늘 함께 했고, 지금도 데이터 EDA (Exploratory Data Analysis)나 간단한 전처리, 모델링을 위해서는 주피터 노트북을 활용하고 있습니다.
하지만 이렇게 분석한 결과나 그래프를 다른 누군가와 공유하고 싶을 때, 특히 파이썬을 아예 실행할 수 없는 환경이나 주피터 노트북 형태가 아닌 웹 애플리케이션의 형태로 공유하고 싶을 때, 주피터 노트북만으로는 충분하지 않은 경우가 많습니다.
웹 애플리케이션을 밑바닥부터 만들어 올리려면 프론트엔드, 백엔드라는 또 다른 큰 분야를 익혀야 하고, 익힌다고 하더라도 주로 파이썬으로 돌아가는 데이터 분석 코드와 자바스크립트로 돌아가는 웹 애플리케이션의 연결다리를 놓는 것도 쉬운 일이 아닙니다. 단지 csv 파일로부터 변형한 데이터프레임과 그래프 몇개를 웹 앱으로 띄우고 싶었을 뿐인데, 배보다 배꼽이 더 커지는 상황이 되어 버리는 것이죠.
이 문제를 해결할 수 있는 방법이 바로 오늘 소개할 Streamlit이라는 서비스입니다.
Streamlit은 오픈 소스 파이썬 라이브러리로, 순수 파이썬으로 작성된 데이터 분석, 데이터 시각화 과정을 깔끔한 웹 UI로 띄워주는 서비스를 제공하고 있습니다. 데이터 웹앱을 개발하고 배포하는데 프론트엔드 지식이 전혀 필요 없다는 것이 streamlit의 가장 큰 이점입니다.
또한 streamlit 자체가 하나의 파이썬 라이브러리이기 때문에, 개발 과정에서 pandas나 numpy를 사용하듯이 바로 설치해 사용할 수 있습니다.
1
pip install streamlit
이 글에서는 streamlit을 활용한 데이터 시각화의 전 과정을 공유하고자 합니다. 공공데이터를 활용해 데이터 전처리 및 시각화, 데이터 웹앱 구성, 웹 앱 배포 등 streamlit 개발의 전체 사이클을 돌아보면서 streamlit을 소개해보도록 하겠습니다.
또한 결과물만을 보는 것이 아니라, 각 단계에서의 고민과 실제 코드를 살펴보도록 하겠습니다. 꼭 streamlit 자체가 아니더라도 데이터 전처리, 시각화 측면에서 모두가 조금이라도 얻어갈 수 있는 글이 되었으면 좋겠습니다.
이 예제에서 나오는 모든 코드는 제 GitHub 레포에서 확인하실 수 있습니다.
로컬 작업 환경
- macOS Sonoma 14.2.1
- OSX arm64 (Apple Silicon)
- zshell
- 2024년 3월 기준 작동하는 것 확인
데이터 분석 시나리오
Streamlit이 데이터 웹 앱 프레임워크이기 때문에 분석을 위한 데이터와 그 데이터를 가지고 어떤 분석을 하고 싶은지의 시나리오가 필요합니다. 이 예시는 public 레포로 공개될 프로젝트를 작성하기 때문에, 공공 데이터 중 하나인 서울 공공자전거 (따릉이) 데이터를 사용하겠습니다.
그 중에서도 서울시 공공자전거의 일별/월별 이용 추세를 분석하고 싶다고 가정하고, 이를 위해 다음 데이터를 가져왔습니다.
각 데이터를 다운 받아 raw_data/ 라는 폴더 안에 각각 넣어줍니다.
우리는 오늘 이 데이터를 통해 일별/월별 서울 공공 자전거의 대여현황 수를 웹 앱으로 시각화하고 배포할 것입니다.
데이터 전처리
세상의 모든 데이터가 그렇듯, 원본 데이터는 일종의 전처리 작업을 거쳐야 합니다. 서울 공공자전거의 경우 데이터 정리가 비교적 잘 되어 있어 크게 건드릴 부분은 없지만, 다음과 같은 전처리가 필요했습니다.
- 한글 칼럼 명을 영어 칼럼 명으로 변환 (가끔 한글이 특정 그래프에서 깨지는 문제 예방)
- 서로 다른 형태로 되어 있는 시간(연월일 또는 연월) 칼럼을 연, 월, 일 칼럼으로 쪼개기
- 전처리한 데이터프레임을 연/월 별로 묶어 저장하기
이 세 과정이 반영된 코드 예시를 보면서 주목할 만한 점 위주로 설명 해보겠습니다. 다음은 서울시 공공자전거 이용정보(일별) 원본 데이터를 전처리 해 daily_usage_data라는 폴더에 저장하는 코드의 발췌입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from seoul_bike_streamlit.paths import (
COLUMN_MAPPER_PATH,
DAILY_DATA_USAGE_PATH,
DAILY_RAW_DATA_PATH,
)
# ... omitted
DATA_NAME = "daily_usage"
logger.info("Cleaning data for %s...", DATA_NAME)
rename_mapper = load_yaml(COLUMN_MAPPER_PATH / f"{DATA_NAME}.yaml")
logger.debug("raw data path: %s", DAILY_RAW_DATA_PATH)
for csv_path in DAILY_RAW_DATA_PATH.rglob("*.csv"):
logger.info("Reading raw data %s", csv_path.name)
df = pd.read_csv(csv_path, encoding="cp949")
df = (
df.pipe(rename_cols, columns=rename_mapper)
.pipe(split_timestamp_ymd)
)
logger.debug("df.columns after cleaning: %s", list(df.columns))
logger.info("Data cleaning successful for data %s", csv_path.name)
for group, df in df.groupby(["year", "month"]):
logger.info("Saving cleaned data for group: %s", group)
year, month = group
df = df.reset_index(drop=True)
df.to_parquet(DAILY_DATA_USAGE_PATH / f"{year}_{str(month).zfill(2)}.parq")
- 파이썬의
print함수 대신logging라이브러리의logger를 사용한 것을 볼 수 있습니다. 이는 개발 과정에서 디버깅을 위해print()문을 넣었다가 개발 과정이 마무리 되면 전부 주석 처리하거나 삭제하는 과정에 비해 이것이 여러모로 편리하고 더 나은 프로그래밍 습관이기 때문입니다. 더 자세한 이유는 이 글의 주제가 아니기 때문에 넘어가지만, 궁금하신 분들은 이 글에서 더 자세히 확인 하실 수 있습니다. COLUMN_MAPPER_PATH,DAILY_RAW_DATA_PATH,DAILY_DATA_USAGE_PATH등 각종 path 변수를 즉석에서 정의해 사용하는 것이 아니라 import 해 사용합니다. 이는 DRY(Don’t Repeat Yourself) 원리를 준수하기 위함입니다. 또한 이 Path는 단순한str이 아니라pathlib.Path입니다. Path를 위해str대신pathlib.Path쓰는 것이 더 좋은 이유 또한 다른 글로 소개하겠습니다. 우선 이 코드에서 바로 볼 수 있는 한 가지 이점은 path에 대해path.rglob("*.csv")로 특정 확장자를 가진 파일 경로만 쉽게 불러올 수 있다는 점입니다.df.rename에 사용되는 column name mapper(딕셔너리)를 코드 상에 두지 않고 다음과 같이 yaml 파일에서 불어옵니다. 이는 일종의 config인 column mapper와 코드를 분리해 DRY (Don’t Repeat Yourself) 원리를 준수하고, config와 code를 분리해 관리하기 위함입니다.1 2 3 4 5 6 7 8 9 10 11
대여일자: timestamp 대여소번호: rent_station_code 대여소: rent_station_name 대여구분코드: rent_type 성별: gender 연령대: age ' 이용건수': rent_count # preceding space is intentional 운동량: exercise_amount 탄소량: carbon_emission 이동거리(M): rent_meter 이용시간(분): rent_minute
- 잘 모르지만 생각보다 유용한 함수가 있는데, 바로
df.pipe입니다. Pandas 연산을 하다보면df = df.some_func(...)처럼df에 어떤 연산을 수행해 다시df에 넣어주는 일이 상당히 흔한데,df.pipe를 사용하면 순서대로 진행되는df를 받아df를 반환하는 함수를 더 깔끔하게 이어붙일 수 있습니다. - 또 잘 놓치지만 유용한 문법이
df.groupby를 iterator로 활용하는 것입니다.for group, df in df.groupby(["year", "month"]):처럼df.groupby를 iterator 삼아 각 group과 해당 그룹의 데이터프레임을 접근해 그룹별 연산을 수행할 수 있습니다.
이렇게 서울시 공공자전거 이용정보(일별) 원본 데이터를 전처리 해 daily_usage_data로 만들었습니다.
유사하게 서울시 공공자전거 이용정보(월별) 원본 데이터를 전처리 해 monthly_usage_data로 만들었습니다.
하지만 여기까지 하더라도 daily_usage_data와 monthly_usage_data의 크기가 너무 커 streamlit에 보내기에 적합하지 않습니다.
우리가 원하는 것은 사용량 데이터만이고, 그것도 각 유저별 사용 데이터가 아닌 일별 총 사용 데이터만을 필요로 함으로, daily_usage_data -> aggregate_daily_usage로 만드는 과정이 추가로 필요합니다. 이 코드 또한 여기에서 확인 가능하지만, 위의 내용과 거의 동일하기에 건너뛰겠습니다.
데이터 시각화
데이터 전처리가 끝났으니, 본격적인 시각화를 진행할 수 있습니다. 파이썬 시각화 라이브러리는 굉장히 많지만, 그 중 Streamlit에서 제공하는 시각화 API에 해당하는 라이브러리를 골라야 수월하게 웹 앱에 그래프를 띄울 수 있습니다.
저는 plotly를 골라서 사용하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
import plotly.express as px
import streamlit as st
# ... omitted
agg_daily_trend_df = agg_daily_trend_df.query("timestamp>=@start_date and timestamp<@end_date")
enable_ols = st.toggle("Show trend line", value=True, key="daily_trend_toggle")
px_chart = px.scatter(agg_daily_trend_df,
x="timestamp",
y="count",
trendline="ols" if enable_ols else None)
st.plotly_chart(px_chart)
- 위 코드는
agg_daily_trend_df라는 데이터프레임을 쿼리한 후, plotly express scatter plot(px.scatter)을 그려 streamlit UI에 띄웁니다. df.query()라는 문법이 등장하는데, 여러모로 자주 사용되는df.loc[]에 비해 column-based 데이터프레임 쿼리에 유리합니다. 이 기회에 df.query 함수를 익혀 판다스 레파토리에 추가하시는 걸 추천드립니다.st.toggle은 말 그대로 토글 버튼을 추가해 사용자의 인풋에 따라 페이지의 상태를 컨트롤 할 수 있게 해줍니다. 이 경우에는 scatter plot에 OLS 추세선을 추가할지 옵션으로 활용하였습니다. 참고로 이trendline옵션은 streamlit이 아닌 plotly에서 지원하는 기능입니다.- 사실 plotly express(
px)나 plotly.graph_objects(go)에 익숙하다면 plotly 그래프를 streamlit에 띄우는 것은st.ploty_chart()함수에 plotly figure를 전달하는 단 한 줄로 끝납니다.
이 결과 다음과 같은 인터렉티브한 그래프를 웹으로 띄울 수 있습니다. Plotly의 줌인/줌아웃, 팬 이동, 호버(마우스를 위에 두었을 때 점의 정보 표시), PNG로 내보내기 등의 기능들이 그대로 지원됨도 알 수 있습니다. 또한 st.toggle으로 넣은 토글을 누를 때마다 추세선의 표시 여부도 실시간으로 바뀜을 확인할 수 있습니다.
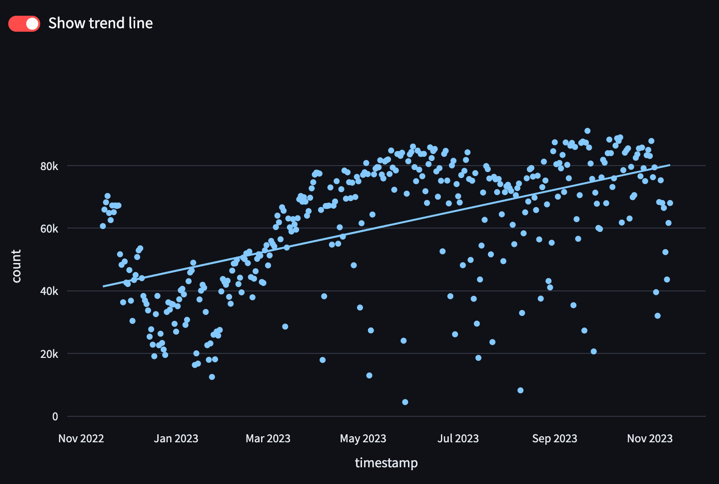
Streamlit 페이지 구성
“데이터 시각화” 영역에서는 streamlit이 plotly 차트를 띄우는 st.ploty_chart() 함수를 살펴보았습니다. 이외에 streamlit 웹 UI에 다양한 UI 컴포넌트를 띄우기 위해서는 streamlit이 지원하는 API를 활용해야 합니다.
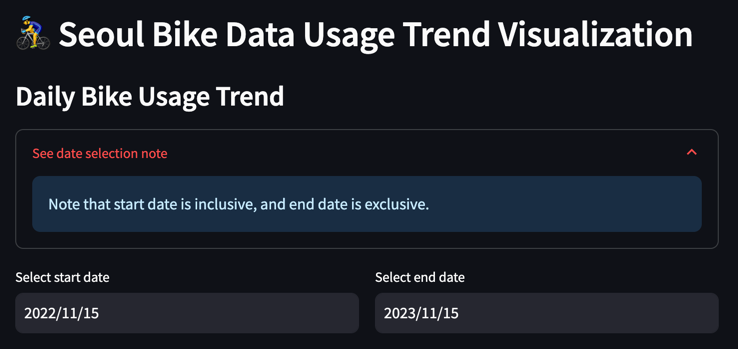
이러한 UI를 구성하기 위한 streamlit API 코드는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import datetime
import streamlit as st
# ... omitted
st.header("🚴♂ Seoul Bike Data Usage Trend Visualization")
st.write("### Daily Bike Usage Trend")
with st.expander("See date selection note"):
st.info("Note that start date is inclusive, and end date is exclusive.")
col1, col2 = st.columns([1, 1])
with col1:
start_date = st.date_input("Select start date",
datetime.date(2022, 11, 15),
key="daily_trend_start")
with col2:
end_date = st.date_input("Select end date",
datetime.date(2023, 11, 15),
key="daily_trend_end")
st.header(), st.write(), st.expander(), st.info(), st.columns(), st.date_input()과 같은 streamlit 함수로 손쉽게 UI 위젯을 구현할 수 있습니다. 특히 date input과 같은 요소는 처음부터 프론트엔드로 구현하기엔 어려운 위젯인데, streamlit이 제공해주니 상당히 편리합니다.
실제로 이 date input 위젯을 통해 날짜를 고르면 즉시 해당 기간에 해당되는 그래프가 다시 그려지는 것을 볼 수 있습니다.
이 글에서 소개된 Streamlit API는 극히 일부분에 불과합니다. Streamlit이 제공하는 모든 API를 보기 위해서는 Streamlit 공식 문서를 참고해주세요.
Streamlit은 별도의 세팅을 하지 않으면 사용자가 위젯의 상태를 조금이라도 바꾸면 전체 스크립트를 다시 처음부터 돌립니다. 이는 시간이 오래 걸리는 데이터 IO나 데이터 연산이 처음부터 돌아가야 함을 의미합니다. 이러한 문제를 streamlit은 자체 캐싱으로 해결하는데, streamlit을 실무에 효과적으로 사용하려면 이 캐싱 기능은 필수입니다. 분량 상 이 글에서는 다를 수 없지만, Streamlit을 실무에 활용하신다면 streamlit 캐싱에 대한 문서을 꼭 참고해주세요.
참고로 streamlit은 파이썬 라이브러리이기 때문에 사용자 입장에서는 전 과정을 100% 파이썬으로 진행할 수 있습니다.
streamlit API 코드를 사용하는 코드를 🚴_Seoul_Bike_Usage_Trend.py라는 파이썬 파일로 담고, 다음과 같이 바로 실행할 수 있습니다.
1
streamlit run 'seoul_bike_streamlit/streamlit/🚴_Seoul_Bike_Usage_Trend.py'
하나의 페이지가 아닌 여러 페이지의 앱을 만드는 기능도 streamlit이 지원해줍니다. 다음과 같이 메인 홈페이지(entrypoint)가 될 py 파일을 두고, 동일한 경로 속 pages/라는 폴더에 다른 페이지를 만들어주면 됩니다.
1
2
3
4
├── 🚴_Seoul_Bike_Usage_Trend.py
├── pages/
│ ├── 🇰🇷_What_is_Seoul_Bike.py
│ └── ...
이때 이 파이썬 파일에 이모지(🚴, 🇰🇷)가 들어간 것을 확인할 수 있습니다. 이는 multi-page streamlit 앱을 만들 때 사이드바에 띄울 페이지 이름 옆에 두는 것으로, 실제 UI에서는 다음과 같이 보입니다.
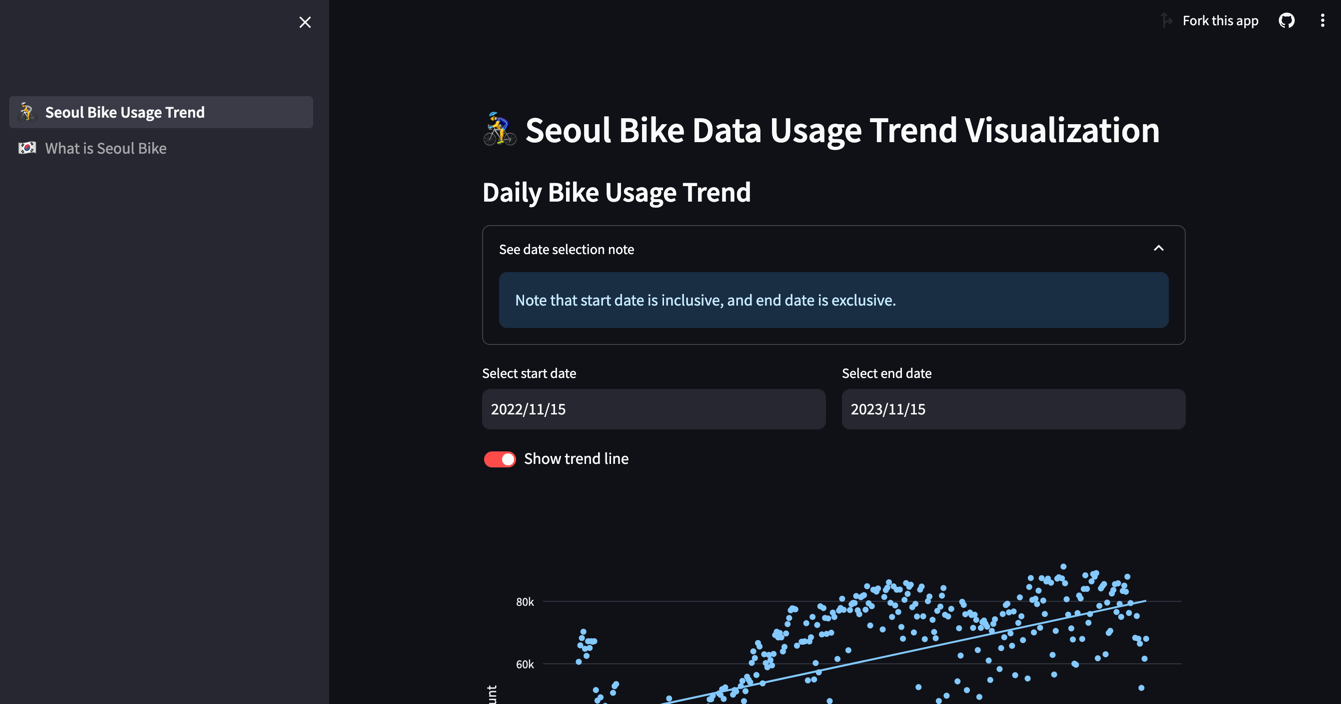
streamlit run 커맨드를 통해 localhost:8501 (기본 포트 값이 8501이고 이 또한 다른 값으로 설정 가능합니다)에 streamlit UI가 뜨고, 수정사항이 즉시 반영되는 hot-reload 기능도 streamlit이 지원해줘서 로컬에서 수월하게 개발 및 디버깅을 진행할 수 있습니다.
제3자 제공 API 활용
혹시라도 그리고자 하는 그래프가 streamlit이나 plotly에 없더라도, 수많은 능력자들이 직접 만든 streamlit과 호환 가능한 API를 활용할 수 있습니다.
지금의 경우 일별 사용량을 scatter plot으로 그렸지만, 이를 달력에 heatmap처럼 시각화하고 싶었습니다. Streamlit 자체 그래프나 plotly에는 이 정확한 기능이 없었지만, plotly-calplot 이라는 프로젝트를 찾았습니다. 이 라이브러리에서 제공하는 calplot은 GitHub Contribution Activity UI와 유사한 날짜별 heatmap을 제공합니다.
이 라이브러리의 경우 pip 으로 바로 설치가 가능하고, plotly와 연동되는 API라 바로 활용할 수 있었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import streamlit as st
from plotly_calplot import calplot
# ... omitted
agg_daily_heatmap_df = agg_daily_heatmap_df.query("timestamp>=@start_date and timestamp<@end_date")
daily_usage_cal_plot = calplot(agg_daily_heatmap_df,
x="timestamp",
y="count",
dark_theme=True,
space_between_plots=0.25,
month_lines=False,
years_title=True,
)
st.plotly_chart(daily_usage_cal_plot)
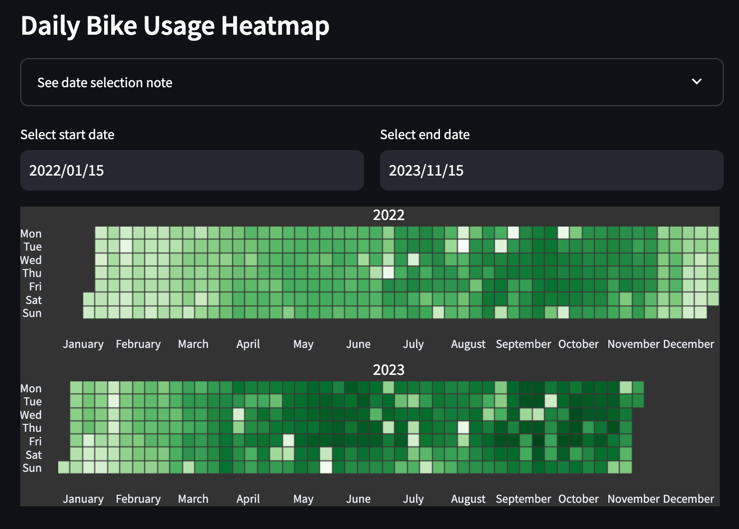
배포
이제 로컬에서의 개발을 마쳤다면, 모두가 볼 수 있도록 앱을 배포할 일만 남았습니다.
어떤 프로젝트를 하더라도 배포하는 과정이 까다롭고 시행착오가 요구되지만, streamlit의 경우 거의 클릭 몇 번으로 바로 배포가 이루어져 상당히 편했습니다.
Streamlit의 자체 배포 서비스는 해당 레포지토리가 Public 레포일 때만 가능하고, 결과물을 Streamlit 커뮤니티의 모두가 볼 수 있다는 조건에서 가능합니다. Streamlit에서는 이를 “Streamlit Community Cloud” deployment라고 합니다. Private 레포의 경우 자체적으로 배포를 진행해야 합니다. 다만 이 경우에도 streamlit 앱을 실행하는 entrypoint 명령어가 개발 시의 streamlit run 명령어와 동일해 Dockerfile을 작성하기가 크게 어렵진 않습니다. Custom deployment에 관한 내용은 여기를 참고해주세요.
우선 public repo에 streamlit 앱에 필요한 코드를 올려두고, 로컬 환경에서 작업했을 때 우측 상단에 있는 “Deploy” 버튼을 누르시면 됩니다.
Deploy 옵션 중 “Streamlit Community Cloud”를 고르고, (위의 콜아웃에서도 말했듯이 이 옵션을 고르면 이 코드가 모두에게 공개됨을 의미합니다) 타겟 GitHub 레포, 타겟 브랜치, main entrypoint file(이 경우 🚴_Seoul_Bike_Usage_Trend.py)와 최종 deploy 될 url을 적어주시면 됩니다. App Url이 최종 배포 되었을 때의 url을 의미하므로, 기존에 존재하는 url들과 겹치지 않으면서 앱의 성격을 잘 반영하는 이름을 골라주세요.
Advanced setting에서는 필요한 파이썬 버전이나(크게 상관은 없을 것이나 로컬 개발 환경과 맞추는 것을 추천합니다), 필요한 환경변수를 설정할 수 있습니다.
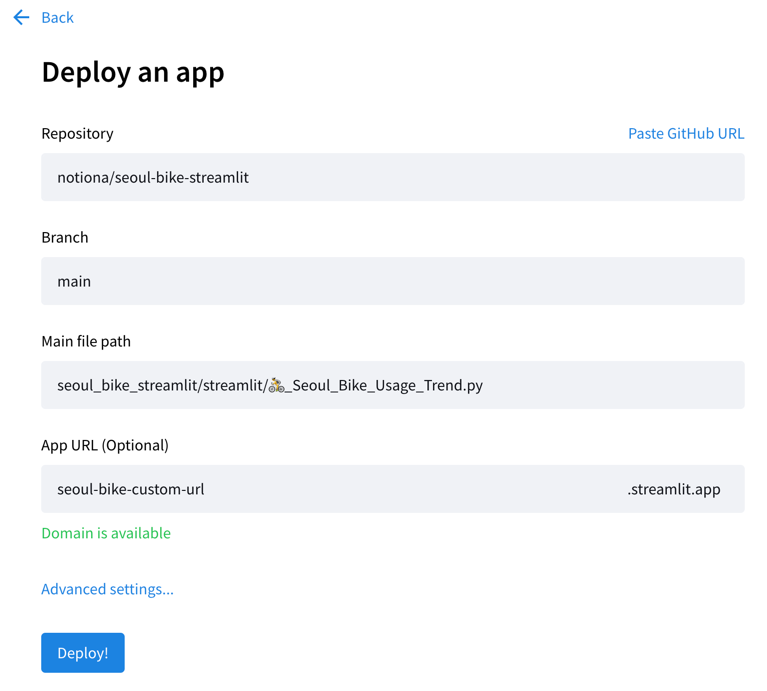
이후 “Deploy!” 버튼을 누르면 귀여운 UI와 함께 배포가 진행됩니다. 배포가 완료되면 app url에 지정한 url에서 배포된 앱을 확인해보세요.
여기까지 공공 데이터를 가지고 데이터 전처리 및 데이터 시각화, streamlit 웹 앱 페이지 구성, 배포까지의 전체 싸이클을 따라가 보았습니다.
직접 이 전체 과정을 한번 따라해보고 싶으시다면, 전 과정이 담긴 제 레포를 fork 해 진행해 보시면 됩니다.
동일한 영어 포스트
Data Analysis & Visualization with Streamlit
참고한 글, 문서
- https://stackoverflow.com/questions/6918493/in-python-why-use-logging-instead-of-print
- https://docs.streamlit.io/library/api-reference/
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.query.html
- https://github.com/brunorosilva/plotly-calplot
- https://docs.streamlit.io/knowledge-base/tutorials/deploy
아직 부족한 점이 많아 미흡하거나 틀린 내용이 있으면 댓글로 알려주시면 감사하겠습니다. 제안이나 질문도 언제든지 남겨주세요! 🙇♂️