Dkron 완전 셋업 - 고가용성 크론을 향해
Dkron 이란?
정해진 시간에 맞춰 어떤 작업을 수행하고 싶을 때 우리는 cron job을 많이 사용합니다. 가장 단순하게 linux의 cron을 사용할 수도 있지만, 기본 cron은 설정한 작업이 정상적으로 작동하지 않거나 어떠한 이유로 트리거 되지 않았더라도 그것을 쉽게 확인할 방법이 없습니다. 또한 cron이 돌고 있는 서비스나 서버에 문제가 생긴다면 cron 또한 작동하지 않게 되고, cron 서비스만 하나 다운되었을 뿐인데 cron에 의지하는 모든 서비스가 제대로 작동하지 않는 SPOF (Single Point of Failure) 문제가 발생합니다.
이 문제를 해결하기 위해서는 high availability (고가용성)가 필요한데, high availibility를 제공하면서 서버 간 소통을 위한 별도의 저장공간을 사용하지 않는 서비스가 바로 dkron 입니다. dkron을 사용한다면 여러 개의 dkron 서버를 띄워 이 중 몇 개의 서버가 다운 되더라도 cron 태스크를 정상적으로 수행할 수 있고, 각 cron 태스크의 성공 여부를 UI로써 확인할 수 있습니다. 이외에도 후술한 여러 기능들을 지원합니다.
dkron의 유일한 단점은 문서가 많지 않아 dkron을 처음부터 끝까지 셋업하는 방법이 (제가 아는 바로는) 알려져 있지 않다는 것입니다..! 🫠
dkron이 제공하는 dkron 공식문서도 있지만, 각 기능을 로컬 코드 단위로 어떻게 구현해야 하는지, 특히 docker만을 활용하는 환경에서 정확히 어떻게 셋업해야 하는 것인지를 제대로 알 수 없습니다. 그렇기에 저도 dkron을 프로젝트에 도입하는 과정에서 제대로 된 자료를 찾지 못해 여러 시행 착오를 겪었고, 이 글은 저와 비슷한 모든 분들을 위한 글입니다.
이 글에서 다루는 dkron의 기능은 다음과 같습니다. 이외의 기능은 dkron 공식문서에서 확인하실 수 있습니다.
- High Availability: dkron을 사용하는 가장 근본적인 이유로, 하나의 서버가 아니라 여러 개 (이 경우에서는 3개)의 동일한 서버를 띄워 몇 개의 서버가 다운 되더라도 여전히 의도한 기능을 가능케 하는 핵심 기능입니다. 여러 서버가 동일한 일을 수행해야 하기 때문에 서로 끊임없이 정보를 공유해야 하는데, dkron은 별도의 데이터베이스 없이 raft 알고리즘으로 서로 소통하고 리더를 선출합니다.
- Configuration: dkron 서버를 실행할 때 command line argument로 서버를 설정해도 되지만, config 파일을 통해 서버를 구성할 수 있습니다.
- Persistence: dkron 서버 전체를 끄고 다시 시작할 때, 일반적인 도커 컨테이너라면 서버 내부에 설정했던 정보인 태스크는 다 날아가야 하지만, dkron 서버 속 데이터 폴더를 호스트 시스템에 볼륨 마운트를 함으로써 태스크를 지속시킬 수 있습니다.
- Tag: cron 태스크를 만들었을 때 어떤 서버가 해당 태스크를 실행해야 하는지 지정할 수 있는 것도 dkron의 핵심 기능중 하나입니다. 가령 총 5개의 서버가 있는데 그 중 메모리가 많이 배정된 3개의 서버에는 메모리가 많이 필요한 태스크를 배정하고, 다른 태스크는 나머지 서버에 배정할 수 있다는 뜻입니다. 이 기능을 가능케 하는 것이 tag라는 기능입니다.
- Python 코드 실행: 기본적으로 dkron의 도커 이미지에는 dkron만 들어있습니다. 그렇기에 dkron이 기본적으로 제공하는 shell, kafka, grpc, http, nats executor 이외에 python 코드를 실행하고 싶다면 dkron 도커 이미지를 기반으로 파이썬을 포함한 새 도커 이미지를 빌드해야 합니다.
- Rolling update: dkron 서버 관련 코드 수정사항이 있을 때 그 수정사항을 반영하기 위해서는 서비스를 내린 후 다시 띄워야 합니다. 하지만 여러 개의 dkron 서버를 띄웠다면, 서버를 하나씩 업데이트 하는 rolling update를 수행해 down time 없이 코드 수정 사항을 모든 서버에 반영할 수 있습니다.
이 글은 각 기능에 어떤 설정이나 코드가 기여하는지 정확히 설명하기 위해 다음과 같이 기능 별로 코드를 구분해 단계적으로 셋업을 진행했습니다.
- High availability
- Configuration, persistence, tag
- Python 코드 실행, rolling update
즉 (2) 는 (1)과 (2)의 기능을 포함한 코드, (3)은 (1), (2), (3) 기능을 모두 포함한 코드를 담고 있습니다.
각 단계의 모든 코드는 제 레포에 정리해 두었습니다.
각 단계는 전 단계의 기능을 포함한 확장이기 때문에, 시간이 급하신 분들은
3-python-rolling-update속 코드만 보시면 됩니다.
로컬 작업 환경
- macOS Sonoma 14.2.1
- OSX arm64 (Apple Silicon)
- zshell
- 2024년 6월 기준 작동하는 것 확인
- Docker version 20.10.17
- Docker Desktop version 4.12.0
- Dkron image: dkron:4.0.0-beta5-light
레포의 코드를 다운 받아 각 단계의 기능을 직접 확인해보세요!
배경지식
이 글을 제대로 이해하기 위해서는 다음과 같은 배경 지식 및 스킬이 필요해요.
- 기본 도커 (키워드: image, build, run, container, network)
- linux 기본 cron 사용법
1. High Availability
- High Availability: dkron을 사용하는 가장 근본적인 이유로, 하나의 서버가 아니라 여러 개 (이 경우에서는 3개)의 동일한 서버를 띄워 몇 개의 서버가 다운 되더라도 여전히 의도한 기능을 가능케 하는 핵심 기능입니다. 여러 서버가 동일한 일을 수행해야 하기 때문에 서로 끊임없이 정보를 공유해야 하는데, dkron은 별도의 데이터베이스 없이 raft 알고리즘으로 서로 소통하고 리더를 선출합니다.
이 실습에서는 3개의 서버를 띄우겠습니다. HA (highly available) 분산 시스템에서는 리더와 팔로워를 선출하는데, 1보다 크면서 과반수를 만들 수 있는 3, 5, 7, 9과 같은 숫자를 흔히 사용하기 때문입니다.
도커를 활성화 한 후, 서버끼리 서로 소통할 수 있도록 우선 도커 네트워크를 하나 만들어줍니다.
1
docker network create cronnet
이제부터가 조금 까다로운 부분입니다. dkron 클러스터를 형성하기 위해서는 클러스터를 구성하는 멤버 서버들이 필요하고, dkron 서버를 시작하기 위해서는 이미 형성된 dkron 클러스터가 있어야 합니다. 이 데드락을 해결하기 위해서 dkron에서 제안하는 방법이 멤버가 하나만 필요한 stand-alone 클러스터를 먼저 구성하고, 이 서버의 IP 주소를 기억했다가 이 IP 주소와 다른 서버들의 IP를 포함해 다시 모든 서버를 띄우는 방식입니다.
하지만 컨테이너를 띄울 때마다 IP가 바뀌는 환경에서는 이 방법을 사용할 수 없습니다. 그래서 제가 발견(?)한 방법은 다음과 같습니다.
1
2
3
4
5
6
docker run -d \
-p 1234:8080 -p 8946 -p 6868 \
--name dkron1 \
--network cronnet \
dkron/dkron:4.0.0-beta5-light \
agent --server --bootstrap-expect=1 --node-name=node1
다음과 같이 bootstrap-expect가 1인, 즉 stand-alone 서버를 띄워 클러스터를 구성한 후 나머지 두 서버를 bootstrap-expect=3에 맞춰 띄웁니다.
1
2
3
4
5
6
7
docker run -d \
-p 1235:8080 -p 8946 -p 6868 \
--name dkron2 \
--network cronnet \
dkron/dkron:4.0.0-beta5-light \
agent --server --bootstrap-expect=3 --node-name=node2 \
--retry-join=dkron1:8946 --retry-join=dkron2:8946 --retry-join=dkron3:8946
이때 retry-join 설정이 이 클러스터에 어떤 peer 서버를 기대하는지 설정하는 부분으로, 지금은 도커 컨테이너의 이름으로 설정했습니다.
dkron에 사용되는 포트는 3 개입니다. 8080은 HTTP UI 서버, 8946은 서버 간 grpc 통신, 6868은 raft 알고리즘에 사용됩니다.
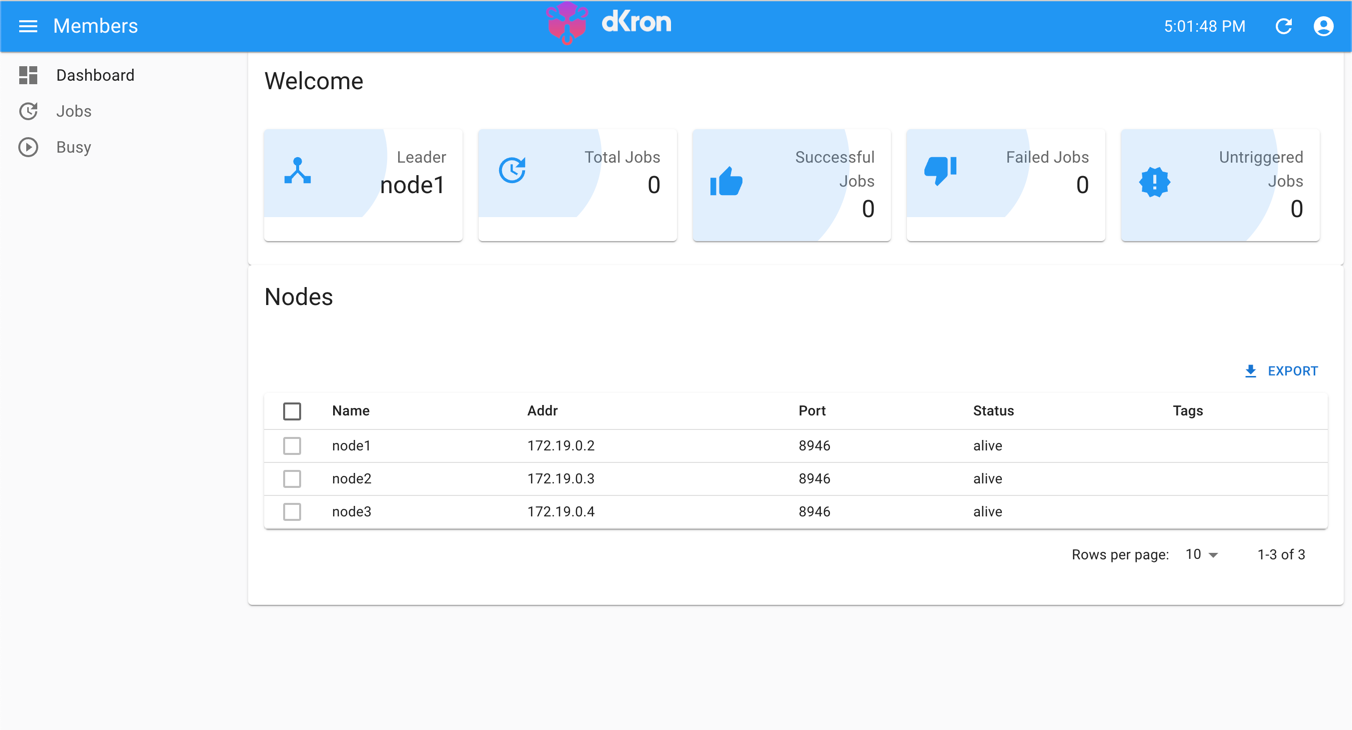
이렇게 세 서버를 띄우면 localhost:1234, localhost:1235, localhost:1236에서 각 서버의 UI 화면을 확인할 수 있습니다. node1을 가장 먼저 띄웠고 클러스터를 형성하는 bootstrap 서버로 사용했기 때문에 리더가 node1임을 확인할 수 있습니다.
2. Configuration, Persistence, Tag
이제는 다음 기능을 추가할 차례입니다.
- Configuration: dkron 서버를 실행할 때 command line argument로 서버를 설정해도 되지만, config 파일을 통해 서버를 구성할 수 있습니다.
- Persistence: dkron 서버 전체를 끄고 다시 시작할 때, 일반적인 도커 컨테이너라면 서버 내부에 설정했던 정보인 태스크는 다 날아가야 하지만, dkron 서버 속 데이터 폴더를 호스트 시스템에 볼륨 마운트를 함으로써 태스크를 지속시킬 수 있습니다.
- Tag: cron 태스크를 만들었을 때 어떤 서버가 해당 태스크를 실행해야 하는지 지정할 수 있는 것도 dkron의 핵심 기능중 하나입니다. 가령 총 5개의 서버가 있는데 그 중 메모리가 많이 배정된 3개의 서버에는 메모리가 많이 필요한 태스크를 배정하고, 다른 태스크는 나머지 서버에 배정할 수 있다는 뜻입니다. 이 기능을 가능케 하는 것이 tag라는 기능입니다.
Configuration은 다음과 같이 yml 파일에 dkron 서버의 여러 요소를 설정하고, 이를 /etc/dkron/dkron.yml이라는 파일로 컨테이너에 넣어줌으로써 설정할 수 있습니다.
Persistence는 data-dir: dkron.data 설정을 통해 dkron 컨테이너 내부에 /dkron.data 경로에 태스크와 관련된 정보를 저장할 것이라고 지정해주고, Dockerfile에서 호스트 시스템에 볼륨 마운트를 해줌으로써 구현됩니다. 이후 모든 서버를 내렸다 다시 켜도 등록한 태스크가 여전히 남아있습니다.
bootstrap 서버 구성에 사용된 YAML 파일과 Dockerfile, 그리고 실행 파일은 다음과 같습니다. 다른 일반 서버 구성에 사용된 파일도 핵심 내용은 동일합니다.
1
2
3
4
5
6
server: true
bootstrap-expect: 1
data-dir: dkron.data
log-level: info
tags:
python: daily
1
2
3
4
5
6
7
8
9
10
FROM dkron/dkron:4.0.0-beta5-light
RUN mkdir -p /etc/dkron
COPY dkron_bootstrap.yml /etc/dkron/dkron.yml
EXPOSE 8080
EXPOSE 8946
EXPOSE 6868
ENTRYPOINT ["dkron", "agent"]
1
2
3
4
5
6
7
8
docker build -t dkron_bootstrap -f Dockerfile.bootstrap .
cur_dir=$(pwd)
docker run -d \
-p 1234:8080 -p 8946 -p 6868 \
--name dkron1 \
--network cronnet \
-v $cur_dir/dkron1.data:/dkron.data \
dkron_bootstrap --node-name=node1
dkron_bootstrap.yml 파일에서 또 한 가지 주목할 부분은 tags 설정입니다. 태그는 dkron 서버에 부여가 가능한데, 어떠한 dkron 태스크가 있을 때 어떤 서버가 해당 태스크를 실행할지, 그리고 몇개의 서버가 해당 태스크를 실행해야 하는지를 설정할 수 있습니다.
태그는 다음과 같이 dkron 태스크를 등록할 때 부여할 수 있습니다. 다음은 매 분 "hello"를 echo 하는 태스크의 예시입니다.
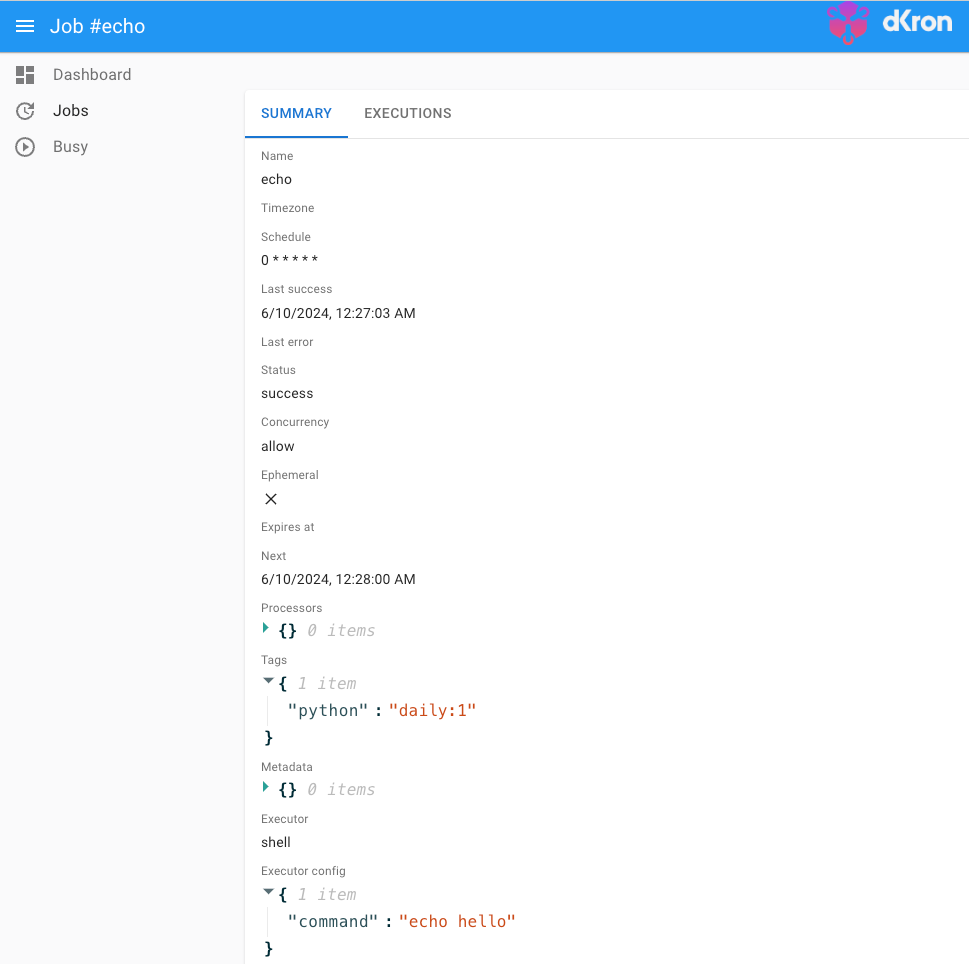
여기서 "python":"daily:1" 영역이 태그인데, 이는 태스크 입장에서 "python: daily" 태그를 가진 서버만 이 태스크를 실행하라는 뜻이고, "python":"daily:1"에서 마지막에 붙은 ":1"은 이 태그를 만족하는 서버 중 하나의 서버만 이 태스크를 수행하라는 의미입니다. 이 서버 숫자를 설정하지 않으면 태그를 만족하는 모든 서버가 동일한 작업을 수행하기에 꼭 필요한 설정입니다.
이렇게 태스크를 만들면 각 실행의 성공 여부와 로그를 확인할 수 있습니다.
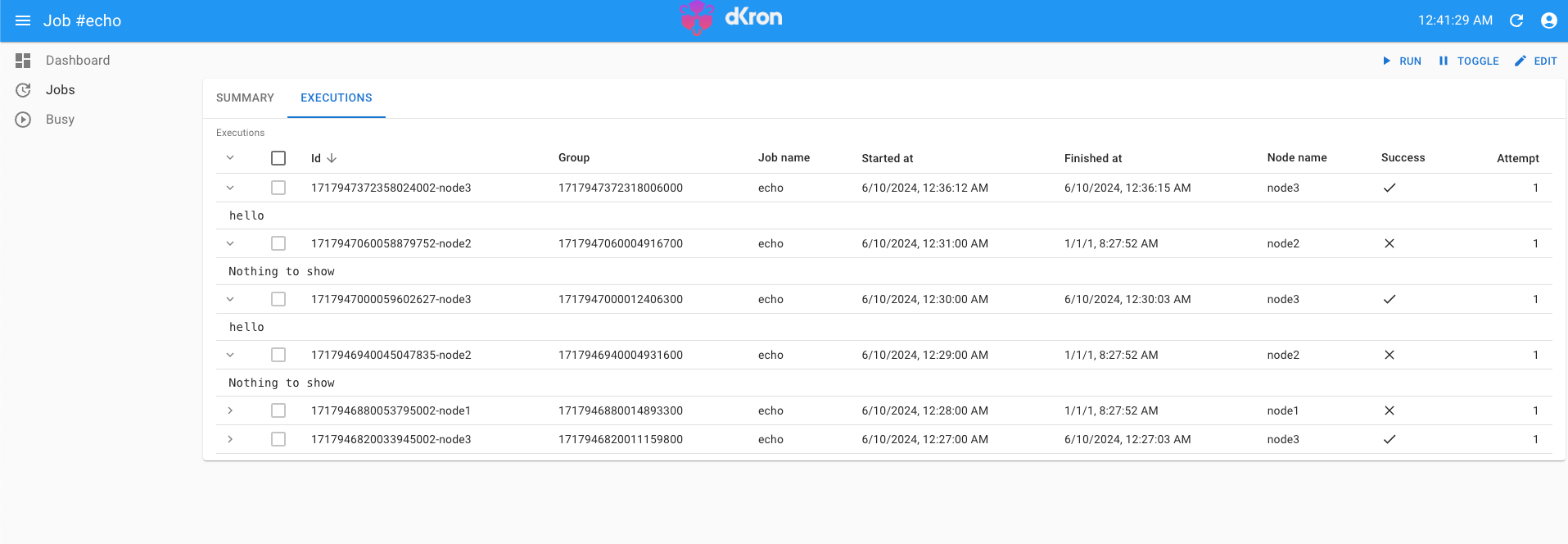
dkron 태스크를 만들고 cron 트리거 시간을 설정하는 것은 linux cron을 사용해본적이 있다면 별도의 설명이 필요 없이 꽤 직관적이라 많이 설명하지 않았습니다. dkron이 제공하는 다양한 executor는 관련 공식 문서에서 확인할 수 있습니다.
3. 파이썬, Rolling Update
이제 완전 셋업을 위해 남은 것은 두 가지, 파이썬 코드를 실행하는 것과 down time 없이 dkron 서버들을 업데이트 하는 rolling update 구현입니다.
- Python 코드 실행: 기본적으로 dkron의 도커 이미지에는 dkron만 들어있습니다. 그렇기에 dkron이 기본적으로 제공하는 shell, kafka, grpc, http, nats executor 이외에 python 코드를 실행하고 싶다면 dkron 도커 이미지를 기반으로 파이썬을 포함한 새 도커 이미지를 빌드해야 합니다.
- Rolling update: dkron 서버 관련 코드 수정사항이 있을 때 그 수정사항을 반영하기 위해서는 서비스를 내린 후 다시 띄워야 합니다. 하지만 여러 개의 dkron 서버를 띄웠다면, 서버를 하나씩 업데이트 하는 rolling update를 수행해 down time 없이 코드 수정 사항을 모든 서버에 반영할 수 있습니다.
dkron 도커 이미지에는 dkron을 위한 핵심 기능만 들어있기에 당연히 python이나 다른 언어의 실행 파일은 포함되어 있지 않습니다. 그런데 dkron 서비스를 통해 파이썬 스크립트를 실행하고 싶다면 어떻게 해야 할까요? 시행착오를 겪긴 했지만, dkron 서비스에 필요한 모든 파일들이 /usr/local/bin에 들어있음을 알았다면 다음과 같이 도커파일을 변경해 multi stage 빌드를 진행하면 됩니다. 다른 언어나 다른 실행파일에 대해서도 이 방법을 응용할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
FROM python:3.11.9-alpine3.20
COPY --from=dkron/dkron:4.0.0-beta5-light /usr/local/bin /usr/local/bin
RUN mkdir -p /etc/dkron
COPY dkron_bootstrap.yml /etc/dkron/dkron.yml
EXPOSE 8080
EXPOSE 8946
EXPOSE 6868
ENTRYPOINT ["dkron", "agent"]
이제 조금 까다로운 rolling update 셋업입니다. HA dkron 셋업이 어려운 이유는, dkron 클러스터를 bootstrapping 하기 위해 첫 서버와 나머지 서버의 configuration을 달리 해야하기 때문입니다. 이상적으로는 모든 서버가 동일한 셋업으로 설정되어 bootstrap 서버가 아닌 일반 서버 설정으로 내렸다가 올렸다가 할 수 있어야 하는데, 첫 bootstrap 서버 때문에 그것이 어려운 상황입니다.
그렇기에 rolling update를 하기 위해서는 우선 dkron 클러스터 속 모든 서버가 bootstrap 서버가 아닌 일반 서버가 되도록 설정해야 합니다. 즉 다음과 같은 순서로 클러스터를 셋업합니다.
- node1을 bootstrap 서버로 설정해 dkron 클러스터를 띄웁니다.
- node2와 node3를 일반 서버로 띄워 dkron 클러스터를 형성합니다.
- node1을 내립니다. 이때 node2나 node3가 클러스터의 새로운 리더가 됩니다.
- node1을 node2와 node3과 같이 일반 서버로 띄워 dkron 클러스터에 참여시킵니다.
(1)과 (2)는 지금까지 이미 한 내용이지만, node1을 내렸다가 다시 일반 서버로 띄우는 작업을 수행하면, 이제 dkron 클러스터의 모든 서버가 bootstrap-expect=3과 retry-join 설정을 가진 일반 서버가 됩니다. 이때부터는 어떤 서버를 내리고 다시 올려도 모두 동일한 config (node-name 제외)로 진행할 수 있습니다.
이 모든 과정이 압축되어 있는 다음 스크립트를 실행하면 위의 클러스터 셋업을 바로 마칠 수 있습니다.
1
2
3
4
sh bootstrap_server1.sh
sh run_server2.sh
sh run_server3.sh
sh run_server1.sh
이제 rolling update를 위해서는 리더를 제외한 나머지 두 서버를 우선 재배포해 새로운 코드를 반영하게 하고, 리더 서버를 마지막으로 재배포 하면 됩니다. 리더가 마지막으로 내려가야 새로운 코드가 반영된 나머지 두 서버 중에서 새로운 리더가 선출되는 것이 보장되어 가장 효과적으로 모든 서버의 코드를 업데이트 할 수 있습니다.
위를 실행한 이후에는 어떠한 서버를 동일한 config(bootstrap_server.yml)로 재배포해도 리더십이 잘 바뀌고, 나머지 서버들은 정상적으로 동작하는 것을 확인할 수 있습니다.
저는 처음에 node-name이 단지 서버의 이름을 지칭하는 부차적인 기능을 하는 줄 알았지만, 재배포를 할때마다 서버 IP가 바뀌는 환경에서는 클러스터 속 멤버 서버를 기억하는데 결정적인 역할을 한다는 사실을 알아내었습니다. 즉 node1을 내리고 다른 IP 주소로 클러스터에 재배포 하는 상황에서 다른 서버들이 이 서버가 방금 내려간 node1이라는 사실을 인식해 더 이상 내려간 node1을 기다리지 않고 새로운 node1을 클러스터 멤버로 받아들이는데 node-name이 활용되는 것입니다.
클러스터 리더십과 같은 분산 시스템의 HA (high availability) 개념이 익숙하지 않다면 kafka와 zookeeper에서의 HA 문서를 참고해주세요.
동일한 영어 포스트
Dkron full setup - towards a more reliable and highly available cron
참고한 글, 문서
- https://dkron.io/docs/basics/getting-started
- https://www.redhat.com/en/resources/high-availability-for-apache-kafka-detail
아직 부족한 점이 많아 미흡하거나 틀린 내용이 있으면 댓글로 알려주시면 감사하겠습니다. 제안이나 질문도 언제든지 남겨주세요! 🙇♂️