Dkron full setup - towards a more reliable and highly available cron
What is Dkron and why do we need it?
When we want to perform a task periodically, we often use cron jobs. While we can simply use Linux’s cron, the basic cron does not provide an easy way to verify if the scheduled tasks are functioning correctly or if they failed to trigger for some reason. Additionally, if there is an issue with the service or server running the cron, the cron will also fail to operate. This results in a Single Point of Failure (SPOF) problem, where all services relying on cron malfunction just because the cron service has stopped working.
To resolve this issue, high availability is necessary. One service that provides high availability without requiring separate storage space for communication between servers is Dkron. By using Dkron, even if several Dkron servers go down, the cron tasks can still be executed correctly on remaining servers, and the success of each cron task can be verified through a UI. Additionally, Dkron supports other useful features, which will be discussed later.
The only drawback of Dkron is that there is not much documentation available, so the method for setting up Dkron with all the necessary features end to end is nowhere to be found…! 🫠 (That is, as far as I know. Please tell me if otherwise)
While Dkron provides official documentation, it does not clearly explain how to implement each feature at the local code level or how to set it up precisely in an environment that uses only Docker. Because of this, I faced several trial and error situations during the process of adopting Dkron for my project due to the lack of proper resources. This article is for everyone who is in a similar situation.
The Dkron features covered in this article include the following. For other features, please refer to the official Dkron documentation.
High Availability: The fundamental reason for using Dkron is its core feature of high availability, which ensures that the intended functions can still be performed even if several servers go down. Since multiple servers must perform the same tasks, they need to continuously share information with each other. Dkron facilitates this communication and leader election using the Raft algorithm without requiring a separate database.
Configuration: While Dkron servers can be configured using command line arguments at runtime, they can also be set up through a configuration file.
Persistence: When the entire Dkron server setup is stopped and restarted, typically all task information configured within the server would be lost in a standard Docker container. However, by volume mounting the data folder within the Dkron server to the host system, tasks can be persisted.
Tag: One of Dkron’s key features is the ability to specify which server should execute a given task using tags. For example, if there are five servers, you can assign memory-intensive tasks to the three servers with more memory, and other tasks to the remaining servers. This functionality is enabled by the tag feature.
Python Code Execution: By default, Dkron’s Docker image only includes Dkron itself. Therefore, if you want to execute Python code in addition to the shell, Kafka, gRPC, HTTP, and NATS executors provided by Dkron, you need to build a new Docker image based on the Dkron image that includes Python.
Rolling Update: When there are code changes related to the Dkron server, these changes need to be applied by stopping and restarting the service. However, if you have multiple Dkron servers running, you can perform a rolling update by updating the servers one by one. This way, the code changes can be applied to all servers without any downtime.
To explain exactly how each setting or code contributes to the functionality, this article proceeds step by step, with the code divided by feature:
- High Availability
- Configuration, Persistence, Tag
- Python Code Execution, Rolling Update
Thus, the code for step (2) includes the features from both (1) and (2), and the code for step (3) encompasses the features from (1), (2), and (3).
All the code for each step is organized in my repository.
Since each step builds upon the previous one, those in a hurry can simply look at the code in the
3-python-rolling-updatefolder.
Local environment
- macOS Sonoma 14.2.1
- OSX arm64 (Apple Silicon)
- zshell
- This tutorial is effective as of June 2024
- Docker version 20.10.17
- Docker Desktop version 4.12.0
- Dkron image: dkron:4.0.0-beta5-light
Feel free to clone my repo and follow along!
Prerequisites
This tutorial assumes the audience to be familiar with the following concepts/tools.
- Basic docker (Keywords: image, build, run, container, network)
- Basic experience with linux cron
1. High Availability
- High Availability: The fundamental reason for using Dkron is its core feature of high availability, which ensures that the intended functions can still be performed even if several servers go down. Since multiple servers must perform the same tasks, they need to continuously share information with each other. Dkron facilitates this communication and leader election using the Raft algorithm without requiring a separate database.
In this tutorial, we will launch three servers. In highly available (HA) distributed systems, it is common to elect leaders and followers using numbers that can form a majority greater than one, such as 3, 5, 7, or 9.
First, after activating Docker, we will create a Docker network to allow the servers to communicate with each other.
1
docker network create cronnet
Now comes the tricky part. To form a Dkron cluster, you need member servers, and to start a Dkron server, you need an already formed Dkron cluster. To resolve this chicken-and-egg problem, the method suggested by Dkron involves first setting up a stand-alone cluster that requires only one member, noting its IP address, and then using this IP address along with the IPs of other servers to launch all servers again.
However, in environments where the IP address changes every time a container is launched, this method is not feasible. So, the method I discovered is as follows:
1
2
3
4
5
6
docker run -d \
-p 1234:8080 -p 8946 -p 6868 \
--name dkron1 \
--network cronnet \
dkron/dkron:4.0.0-beta5-light \
agent --server --bootstrap-expect=1 --node-name=node1
We form a dkron cluster by deploying a stand-alone server with bootstrap-expect=1, and deploy the other two with bootstrap-expect=3, to this already formed cluster.
1
2
3
4
5
6
7
docker run -d \
-p 1235:8080 -p 8946 -p 6868 \
--name dkron2 \
--network cronnet \
dkron/dkron:4.0.0-beta5-light \
agent --server --bootstrap-expect=3 --node-name=node2 \
--retry-join=dkron1:8946 --retry-join=dkron2:8946 --retry-join=dkron3:8946
The retry-join option configures which peer servers to expect in this cluser. In this case it would be the container name.
There are three ports required by dkron. 8080 is used for the HTTP UI server, 8946 for the inter-server grpc communication, and 6868은 for the raft algorithm.
You can now check localhost:1234, localhost:1235, localhost:1236 for each server’s UI dashboard. We can see node1 is the leader as it was deployed first as the bootstrap server to initialize the cluster.
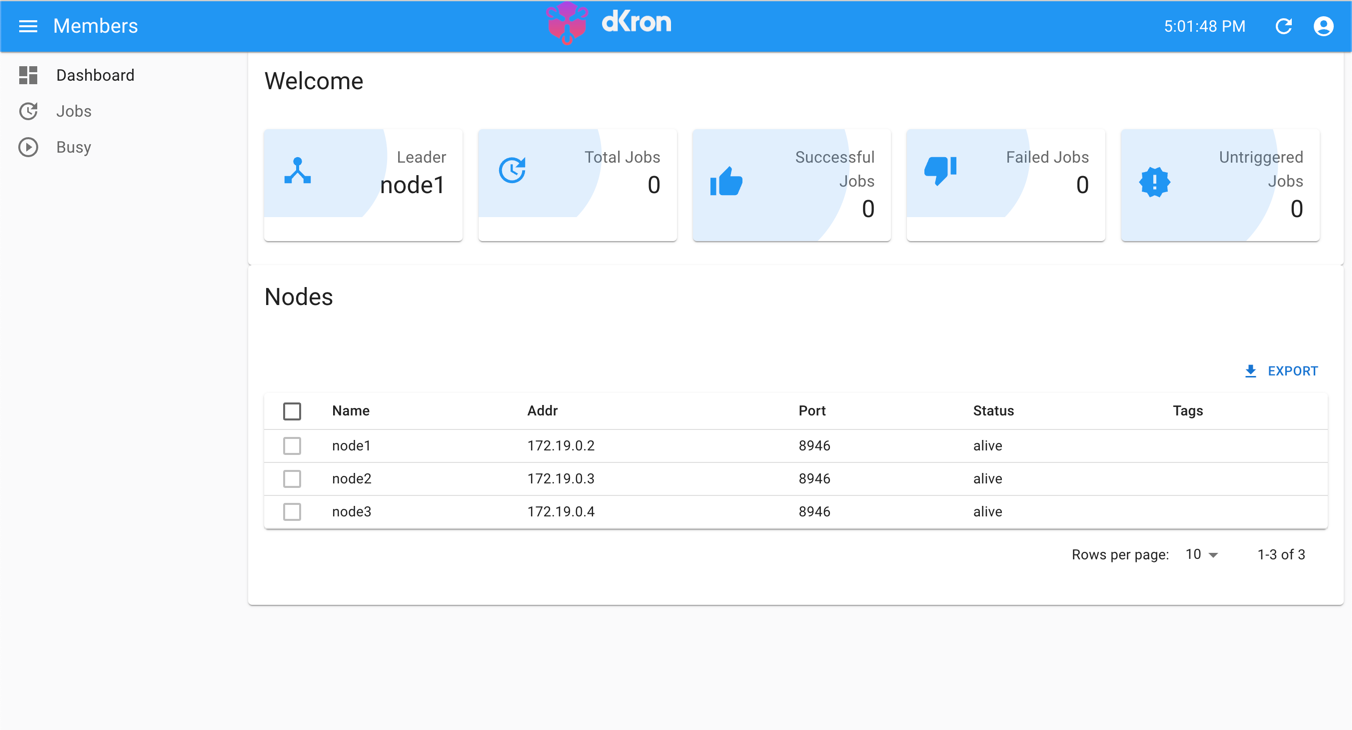
2. Configuration, Persistence, Tag
Now to add the following features, on top of what we have already.
- Configuration: While Dkron servers can be configured using command line arguments at runtime, they can also be set up through a configuration file.
- Persistence: When the entire Dkron server setup is stopped and restarted, typically all task information configured within the server would be lost in a standard Docker container. However, by volume mounting the data folder within the Dkron server to the host system, tasks can be persisted.
- Tag: One of Dkron’s key features is the ability to specify which server should execute a given task using tags. For example, if there are five servers, you can assign memory-intensive tasks to the three servers with more memory, and other tasks to the remaining servers. This functionality is enabled by the tag feature.
Configuration and Persistence
To configure the Dkron server, you can create a YAML file that sets various elements of the Dkron server. This file needs to be placed inside the container at /etc/dkron/dkron.yml.
For persistence, you specify the data-dir: /dkron.data setting, indicating that task-related information will be stored in the /dkron.data path inside the Dkron container. By volume mounting this path to the host system, you ensure that registered tasks are persisted even if all servers are stopped and restarted.
Here are the YAML configuration file, Dockerfile, and run command used for the bootstrap server configuration. The files for other general servers follow the same core changes.
1
2
3
4
5
6
server: true
bootstrap-expect: 1
data-dir: dkron.data
log-level: info
tags:
python: daily
1
2
3
4
5
6
7
8
9
10
FROM dkron/dkron:4.0.0-beta5-light
RUN mkdir -p /etc/dkron
COPY dkron_bootstrap.yml /etc/dkron/dkron.yml
EXPOSE 8080
EXPOSE 8946
EXPOSE 6868
ENTRYPOINT ["dkron", "agent"]
1
2
3
4
5
6
7
8
docker build -t dkron_bootstrap -f Dockerfile.bootstrap .
cur_dir=$(pwd)
docker run -d \
-p 1234:8080 -p 8946 -p 6868 \
--name dkron1 \
--network cronnet \
-v $cur_dir/dkron1.data:/dkron.data \
dkron_bootstrap --node-name=node1
One more noteworthy part in the dkron_bootstrap.yml file is the tags setting. Tags can be assigned to Dkron servers, and they allow you to configure which server will execute a particular Dkron task and how many servers should execute the task.
Tags can be assigned when registering a Dkron task as shown below. Here is an example task to echo hello every minute.
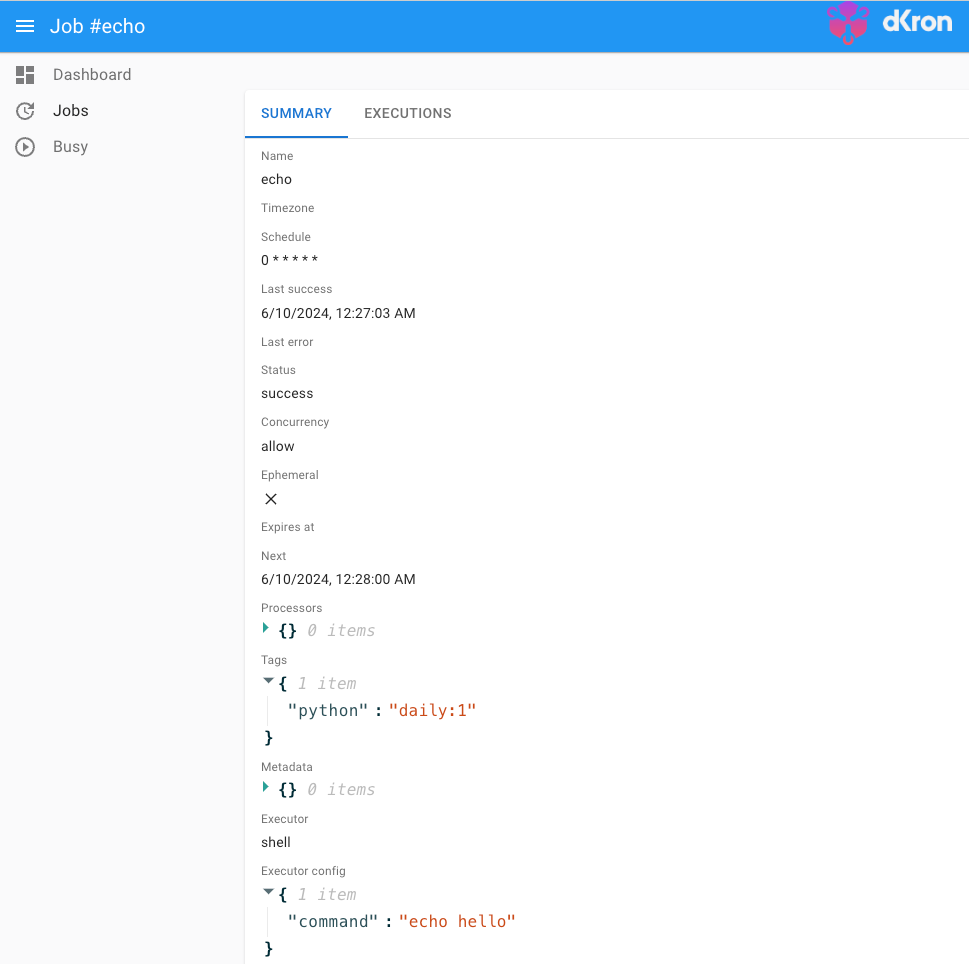
Here, the "python":"daily:1" section represents tags. This means that from the task’s perspective, only servers with the tag "python: daily" will execute this task, and the ":1" appended at the end of "python":"daily:1" signifies that only one server among those satisfying this tag should perform this task. Specifying this server number is crucial as it ensures that all servers satisfying the tag perform the same task. In other words, if you don’t set this number, all three servers will echo hello.
By creating tasks in this manner, you can monitor the success of each execution and view the logs.
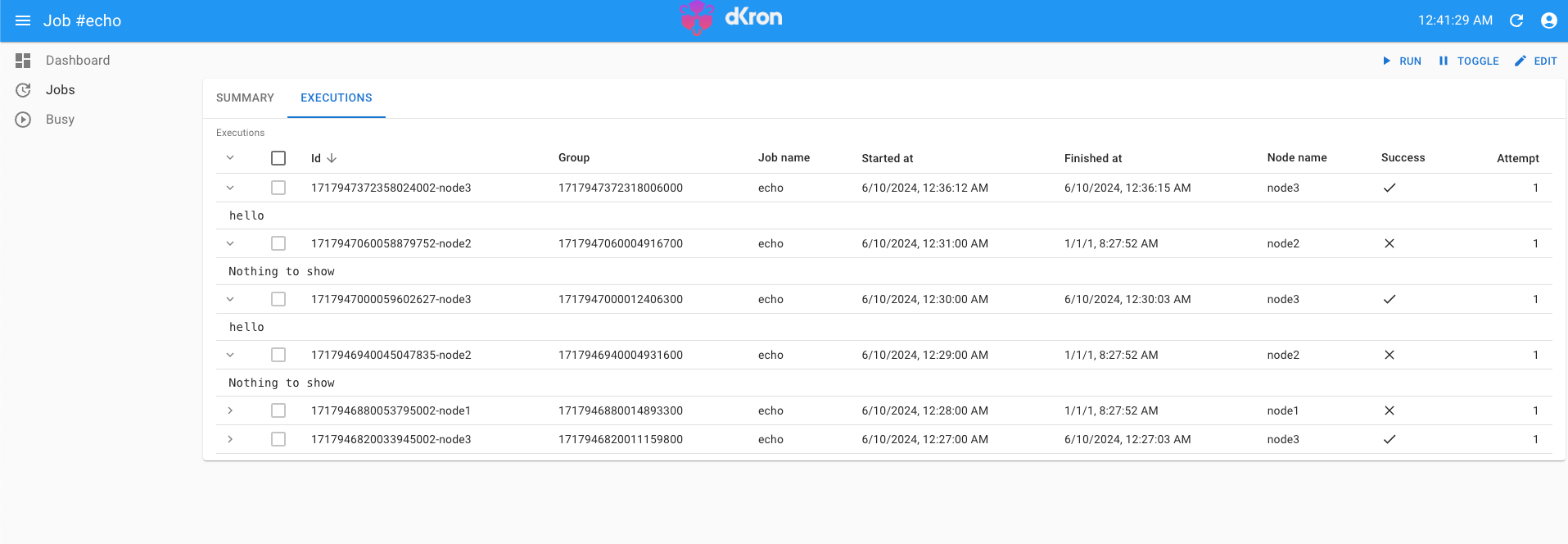
Creating dkron tasks and setting cron trigger times is quite intuitive if you have experience with using Linux cron, so I didn’t elaborate on it extensively. You can find information about the various executors provided by dkron in the official documentation.
3. Python, Rolling Update
Now we have two features left - python code execution and rolling update.
Python Code Execution: By default, Dkron’s Docker image only includes Dkron itself. Therefore, if you want to execute Python code in addition to the shell, Kafka, gRPC, HTTP, and NATS executors provided by Dkron, you need to build a new Docker image based on the Dkron image that includes Python.
Rolling Update: When there are code changes related to the Dkron server, these changes need to be applied by stopping and restarting the service. However, if you have multiple Dkron servers running, you can perform a rolling update by updating the servers one by one. This way, the code changes can be applied to all servers without any downtime.
By default, the dkron Docker image only contains dkron itself, without including Python or other language executables. Therefore, if you want to execute Python scripts or any other language’s code through dkron, you need to build a new Docker image based on the dkron image but including the necessary language runtime, like follows.
1
2
3
4
5
6
7
8
9
10
11
12
FROM python:3.11.9-alpine3.20
COPY --from=dkron/dkron:4.0.0-beta5-light /usr/local/bin /usr/local/bin
RUN mkdir -p /etc/dkron
COPY dkron_bootstrap.yml /etc/dkron/dkron.yml
EXPOSE 8080
EXPOSE 8946
EXPOSE 6868
ENTRYPOINT ["dkron", "agent"]
Now, let’s discuss the slightly more intricate setup for rolling updates. The reason why setting up an HA dkron is challenging is because the configuration of the first server (bootstrap server) differs from that of the rest of the servers. Ideally, all servers should have the same setup so that they can be brought down and up again with the same configuration, regardless of whether they were bootstrap servers or regular servers in the initial cluster formation. However, due to the presence of the initial bootstrap server, achieving this is difficult.
Therefore, to perform a rolling update, all servers in the dkron cluster must first be configured as regular servers, not bootstrap servers. Here’s the process for setting up the cluster:
- Set up node1 as the bootstrap server and launch the dkron cluster.
- Launch node2 and node3 as regular servers to form the dkron cluster.
- Bring down node1. At this point, either node2 or node3 will become the new leader of the cluster.
- Bring up node1 as a regular server, along with node2 and node3.
Steps (1) and (2) have already been covered, but bringing down node1 and bringing it back up as a regular server will ensure that all servers in the dkron cluster have the same configuration with bootstrap-expect=3 and retry-join. From this point on, regardless of which server is brought down and brought back up, they will all proceed with the same configuration (excluding node-name).
The following script encapsulates all the steps discussed above, to setup a dkron cluster withe regular servers.
1
2
3
4
sh bootstrap_server1.sh
sh run_server2.sh
sh run_server3.sh
sh run_server1.sh
Now, for the rolling update, you can redeploy the other two servers first, excluding the leader, to reflect the new code. Then, redeploy the leader server. Ensuring that the leader goes down last guarantees that a new leader is elected from the other two servers that have already been updated with the new code, effectively updating the code on all servers most efficiently.
After executing the above steps, you can redeploy any server with the same configuration (bootstrap_server.yml). You’ll observe that leadership changes smoothly, and the remaining servers operate as expected.
Initially, I thought
node-namewas merely a supplementary feature indicating the server’s name. However, in an environment where server IPs change with each redeployment, I discovered that it plays a crucial role in remembering member servers in the cluster during redeployment. Specifically, when bringing down node1 and redeploying it to a different IP address in the cluster, other servers recognize that the recently brought down server was node1, allowing them to accept the new node1 as a member of the cluster without waiting for the old node1. So settingnode-names is important.
If concepts like cluster leadership in distributed systems and high availability (HA) are unfamiliar, you can refer to documentation on HA in systems like Kafka and Zookeeper for further understanding.
Equivalent Korean Post
References
- https://dkron.io/docs/basics/getting-started
- https://www.redhat.com/en/resources/high-availability-for-apache-kafka-detail
Please feel free to point out any inaccurate or insufficient information. Also, please feel free to leave any questions or suggestions in the comments. 🙇♂️